本篇介绍几个经典的语音合成模型。
什么是语音合成
语音合成是通过文字人工生成人类声音, 也可以说语音生成是给定一段文字去生成对应的人类读音。 这里声音是一个连续的模拟的信号。而合成过程是通过计算机, 数字信号去模拟。 这里就需要数字信号处理模拟信号信息,详细内容可参考 [1]。
Fig. 1 an example of voice signal.
图片1, 就是一个例子用来表示人类声音的信号图。 这里横轴是时间, 纵轴是声音幅度大小。声音有三个重要的指标,振幅(amplitude), 周期(period)和频率(frequency)。 振幅指的是波的高低幅度,表示声音的强弱,周期和频率互为倒数的关系, 用来表示两个波之间的时间长度,或者每秒震动的次数。 而声音合成是根据声波的特点, 用数字的方式去生成类似人声的频率和振幅, 即音频的数字化。了解了音频的数字化,也就知道了我们要生成的目标函数。
音频的数字化主要有三个步骤。
取样(sampling):在音频数字化的过程,采样是指一个固定的频率对音频信号进行采样, 采样的频率越高, 对应的音频数据的保真度就越好。 当然, 数据量越大,需要的内存也就越大。 如果想完全无损采样, 需要使用Nyquist sampling frequency, 就是原音频的频率2倍。
量化 (quantization): 采样的信号都要进行量化, 把信号的幅度变成有限的离散数值。比如从0 到 1, 只有 四个量化值可以用0, 0.25, 0.5, 0.75的话, 量化就是选择最近的量化值来表示。
编码 (coding):编码就是把每个数值用二进制的方式表示, 比如上面的例子, 就可以用2bit 二进制表示, 00, 01, 10, 11。 这样的数值用来保存在计算机上。
采样频率和采样量化级数是数字化声音的两个主要指标,直接影响声音的效果。 对于语音合成也是同样, 生成更高的采样频率和更多多的量化级数(比如16 bit), 会产生更真实的声音。 通常有三个采样频率标准:
1. 44.1kHz 采样, 用于高品质CD 音乐
2. 22.05kHz 采样, 用于语音通话, 中品质音乐
3. 11.025kHz 采样, 用于低品质声音。
而量化标准一般有8位字长(256阶)低品质量化 和16位字长(65536阶)高品质量化。
还有一个重要参数就是通道(channel), 一次只采样一个声音波形为单通道, 一次采样多个声音波形就是多通道。
所以在语音合成的时候,产生的数据量是 数据量=采样频率\ 量化位数*声道数, 单位是bit/s。 一般声道数都假设为1.。 *采样率和量化位数都是语音合成里的重要指标,也就是设计好的神经网络1秒钟必须生成的数据量。
语音合成流程
Fig. 2 Two stage text-to-speech synthsis (source [2])
文本分析(text analysis)
文本分析就是把文字转成类似音标的东西。 比如下图就是一个文本分析,用来分析 “PG&E will file schedules on April 20. ” 文本分析主要有三个步骤:文字规范化, 语音分析, 还有韵律分析。 下面一一道来。
Fig. 3 文本分析
文本规范化 (Text normalization)
文本分析首先是要确认单词和句子的结束。 空格会被用来当做隔词符. 句子的结束一般用标点符号来确定, 比如问号和感叹号 (?!), 但是句号有的时候要特别处理。 因为有些单词的缩写也包含句号, 比如 str. “My place on Main Str. is around the corner”. 这些特别情况一般都会采取规则(rule)的方式过滤掉。
接下来 是把非文字信息变成对应的文字, 比如句子中里有日期, 电话号码, 或者其他阿拉伯数字和符号。 这里就举个例子, 比如, I was born April 14. 就要变成, I was born April fourteen. 这个过程其实非常繁琐,现实文字中充满了 缩写,比如CS, 拼写错误, 网络用语, tmr —> tomorrow. 解决方式还是主要依靠rule based method, 建立各种各样的判断关系来转变。
语音分析 (Phonetic analysis)
语音分析就是把每个单词中的发音单词标出来, 比如Fig. 3 中的P, 就对应p和iy, 作为发音。 这个时候也很容易发现,发音的音标和对应的字母 不是一一对应的关系,反而需要音标去对齐 (allignment)。 这个对齐问题很经典, 可以用很多机器学习的方法去解决, 比如Expectation–maximization algorithm.
韵律分析 (Prosody analysis)
韵律分析就是英语里的语音语调, 汉语中的抑扬顿挫。 我们还是以英语为例, 韵律分析主要包含了: 重音 (Accent),边界 (boundaries), 音长 (duration),主频率 (F0)。
重音(Accent)就是指哪个音节发生重一点。 对于一个句子或者一个单词都有重音。 单词的重音一般都会标出来,英语语法里面有学过, 比如banana 这个单词, 第二个音节就是重音。 而对于句子而言,一样有的单词会重音,有的单词会发轻音。 一般有新内容的名词, 动词, 或者形容词会做重音处理。 比如下面的英语句子, surprise 就会被重音了, 而句子的重音点也会落到单词的重音上, 第二个音节rised, 就被重音啦。 英语的重音规则是一套英语语法,读者可以自行百度搜索。
I’m a little surprised to hear it characterized as upbeat.
边界 (Boundaries) 就是用来判断声调的边界的。 一般都是一个短语结束后,有个语调的边界。 比如下面的句子, For language, 就有一个边界, 而I 后面也是一个边界.
For language, I , the author of the blog, like Chinese.
音长(Duration)就是每个音节的发声长度。 这个通俗易懂。 NLP 里可以假定每个音节单词长度相同都是 100ms, 或者根据英语语法, 动词, 形容词之类的去确定。 也可以通过大量的数据集去寻找规律。
主频率 (F0)就是声音的主频率。 应该说做傅里叶转换后, 值 (magnitude) 最大的那个。 也是人耳听到声音认定的频率。一个成年人的声音主频率在 100-300Hz 之间。 这个值可以用 线性回归来预测, 机器学习的方法预测也可以。一般会认为,人的声音频率是连续变化的,而且一个短语说完频率是下降趋势。
文本分析就介绍完了,这个方向比较偏语言学, 传统上是语言学家的研究方向,但是随着人工智能的兴起,这些feature 已经不用人为设计了,可以用端到端学习的方法来解决。 比如谷歌的文章 TACOTRON: TOWARDS END-TO-END SPEECH SYNTHESIS 就解救了我们。
声波生成(waveform synthesis)
这个部分就比较像我们算法工程师的工作内容了。 在下面, 会详细介绍如何用Wavenet 和WaveRNN 来实现这一步骤的。
这里说所谓的waveform synthesis 就是用这些 语言特征值(text features)去生成对应的声波,也就是生成前文所说的采样频率 和 振幅大小(对应的数字信号)。 这里面主要有两个算法。
串接合成(concatenative speech synthesis): 这个方法呢, 就是把记录下来的音节拼在一起来组成一句话,在通过调整语音语调让它听起来自然些。 比较有名的有双音节拼接(Diphone Synthesis) 和单音节拼接(Unit Selection Synthesis)。这个方法比较繁琐, 需要对音节进行对齐(alignment), 调整音节的长短之类的。
参数合成 (Parametric Synthesis): 这个方法呢, 需要的内存比较小,是通过统计的方法来生成对应的声音。 模型一般有隐马尔科夫模型 (HMM),还有最近提出的神经网络算法Wavenet, WaveRNN.
对于隐马尔科夫模型的算法, 一般都会生成梅尔频率倒谱系数 (MFCC),这个是声音的特征值。 感兴趣的可以参考这篇博客去了解 MFCC。
对于神经网络的算法来说, 一般都是生成256 个 quantized values 基于softmax 的分类器, 对应 声音的 256 个量化值。 WaveRNN 和wavenet 就是用这种方法生成的。
Tacotron和Tacotron2
以下内容主要来源于论文阅读笔记:Tacotron和Tacotron2。
我们首先对 Tacotron 和 Tacotron2 论文中的关键部分进行阐述和总结,之所以两篇论文放在一起,是因为方便比较模型结构上的不同点,更清晰的了解 Tacotron2 因为改进了哪些部分,在性能上表现的比 Tacotron 更好。
语音合成系统通常包含多个阶段,例如 TTS Frontend(文本前端),Acoustic model(声学模型) 和 Vocoder(声码器),如下图更直观清晰一点:
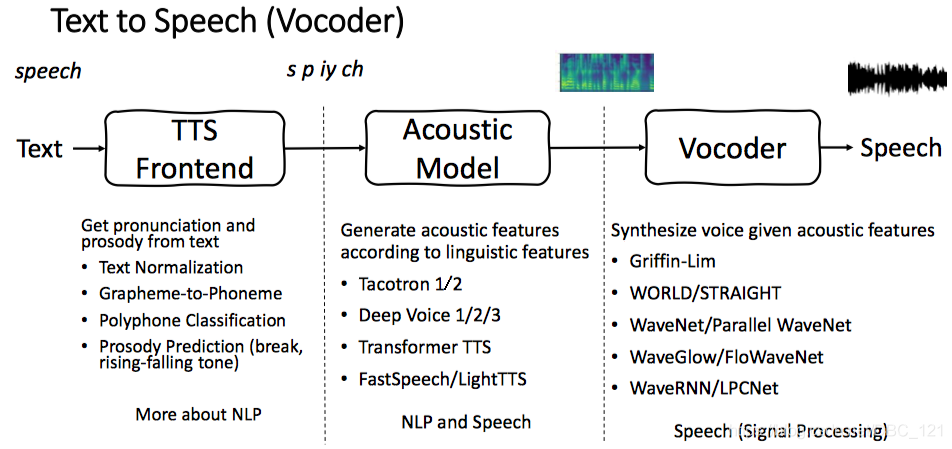
构建这些组件通常需要广泛的领域专业知识,并且可能包含脆弱的设计选择。在很多人困扰于繁杂的特征处理的时候,Google 推出了 Tacotron,一种从文字直接合成语音的端到端的语音合成模型,虽然在效果上相较于传统方法要好,但是相比 Wavenet 并没有明显的提升(甚至不如 Wavenet),不过它更重要的意义在于 end-to-end(Wavenet 是啥将在后面对比 vocoder 的时候讲解,顺便提一下 Tacotron 使用的是 Griffin-Lim 算法,而 Tacotron2 使用的是修改版 Wavenet)。此外,相较于其他样本级自回归方法合成语音,Tacotron 和 Tacotron2 是在帧级生成语音,因此要快得多。
在传统的 Pipeline 的统计参数 TTS,通常有一个文本前端提取各种语言特征,持续时间模型,声学特征预测模型和基于复杂信号处理的声码器。而端到端的语音合成模型,只需要对文本语音进行简单的处理,就能喂给模型进行学习,极大的减少的人工干预,对文本的处理只需要进行文本规范化以及分词 token 转换(论文中使用 character,不过就语音合成而言,使用 Phoneme 字典更佳),关于文本规范化(数字、货币、时间、日期转完整单词序列)以及 text-to-phoneme 可以参见利器:TTS Frontend 中英 Text-to-Phoneme Converter,附代码。端到端语音合成系统的优点如下:
- 减少对特征工程的需求
- 更容易适应新数据(不同语言、说话者等)
- 单个模型可能比组合模型更健壮,在组合模型中,每个组件的错误都可能叠加而变得更加复杂
端到端语音合成模型的困难所在:
不同 Speaker styles 以及不同 pronunciations 导致的对于给定的输入,模型必须对不同的信号有着更大的健壮性,除此之外 Tacotron 原本下描述:
TTS is a large-scale inverse problem: a highly compressed source (text) is “decompressed” into audio
上面这句是 Tacotron 原文中说的,简单来说就是 TTS 输出是连续的,并且输出序列(音频)通常比输入序列(文本)长得多,导致预测误差迅速累积。想要了解更多关于语音合成的背景知识,可以参考文章 Text-to-speech。
Tacotron模型结构
Tacotron 的基础架构是带有注意力机制(Attention Mechanism)的 Seq2Seq 模型,下图是模型的总体架构。网络部分大体可分为 4 部分,分别是左:Encoder、中:Attention、右下:Decoder、右上:Post-processing。从高层次上讲,模型将字符作为输入,并生成频谱图,然后将其转换为波形。
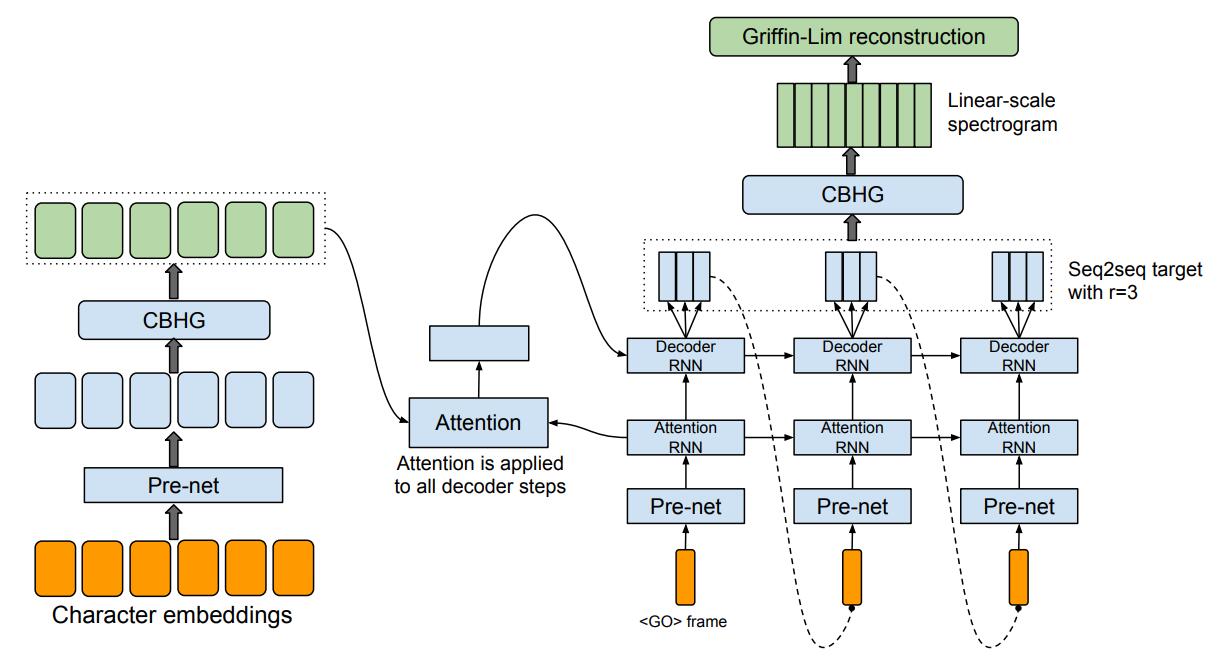
要特别说明的是架构中,raw text 经过 pre-net 后,将会把输出喂给一个叫 CBHG 的模块以映射为 hidden representation,再之后 decoder 会生成 Linear-Spectrum,再经过 Griffin-Lim 转换为波形。
raw text的选择可以可以有多种选择,以中文和英文合成系统为例:
英文文本,训练英文模型,最直观的想法是直接将英文文本当做输入,Tacotron1 也是这么做的。但这样可能会引入一些问题,比如未登录词发音问题。
英文注音符,用英文注音符(比如 CMUDict )作为输入可以提高发音稳定性,除了注音词典,还可以引入注音前端,增强对模型的控制。 中文拼音,由于中文汉字数量多,且存在大量多音字,直接通过文本训练
中文拼音,由于中文汉字数量多,且存在大量多音字,直接通过文本训练是不现实的。所以我们退而求其次,通过拼音训练模型,拼音有注音前端生成,既去掉了汉字的冗余发音又提高了模型的可控性。
中文|英文 IPA (International Phonetic Alphabet) 音标,IPA 音标是一种更强的注音体系,一套注音体系可以标注多种语言。对于中文,IPA 音标的标注粒度比拼音更细,实验中,我们观察到用 IPA 作为输入,可以略微提升对齐稳定性。另外,在中文发音人+英文发音人混合训练试验中,我们观察到了一个有意思的现象:由于中英文 IPA 标注中共享了部分发音单元,导致跨语种发音人可以学会对方的语言,也就是中文发音人可以合成英文,英文发音人可以合成中文。在这个联合学习过程中存在着迁移学习的味道。
根据不同的用途,Tacotron 可以输出 Linear-Spectrum 或 Mel-Spectrum,如果使用 Griffin-Lim 需要 Tacotron 输出 Linear-Spectrum;如果使用 WaveNet 做 Vocoder(即Tacotron2,下文会介绍) ,则 Tacotron 输出 Linear-Spectrum 或 Mel-Spectrum 均可,但 Mel-Spectrum 的计算代价显然更小,Tacotron2 中,作者使用 80 维 Mel-Spectrum 作为 WaveNet Vocoder 的输入。
Character Embedding
我们知道在训练模型的时候,我们拿到的数据是一条长短不一的(text, audio)的数据,深度学习的核心其实就是大量的矩阵乘法,对于模型而言,文本类型的数据是不被接受的,所以这里我们需要先把文本转化为对应的向量。这里涉及到如下几个操作
构造字典
因为纯文本数据是没法作为深度学习输入的,所以我们首先得把文本转化为一个个对应的向量,这里我使用字典下标作为字典中每一个字对应的id,然后每一条文本就可以通过遍历字典转化成其对应的向量了。所以字典主要是应用在将文本转化成其在字典中对应的id,根据语料库构造,这里我使用的方法是根据语料库中的字频构造字典(我使用的是基于语料库中的字构造字典,有的人可能会先分词,基于词构造。不使用基于词是现在就算是最好的分词都会有一些误分词问题,而且基于字还可以在一定程度上缓解OOV的问题)。
然后我们就可以将文本数据转化成对应的向量作为模型的输入。
embed layer
光有对应的id,没法很好的表征文本信息,这里就涉及到构造词向量,关于词向量不在说明,网上有很多资料,模型中使用词嵌入层,通过训练不断的学习到语料库中的每个字的词向量。
值得注意的是,这里是随机初始化词嵌入层,另一种方法是引入预先在语料库训练的词向量(word2vec),可以在一定程度上提升模型的效果。
音频特征提取
对于音频,我们主要是提取出它的mel-spectrogram,然后变换得到比较常用的音频特征MFCC。对于声音来说,它其实是一个一维的时域信号,直观上很难看出频域的变化规律,我们知道,可以使用傅里叶变化,得到它的频域信息,但是又丢失了时域信息,无法看到频域随时域的变化,这样就没法很好的描述声音, 为了解决这个问题,很多时频分析手段应运而生。短时傅里叶,小波,Wigner分布等都是常用的时频域分析方法。这里我们使用短时傅里叶。
所谓短时傅里叶变换,顾名思义,是对短时的信号做傅里叶变化。那么短时的信号怎么得到的? 是长时的信号分帧得来的。这么一想,STFT的原理非常简单,把一段长信号分帧(傅里叶变换适用于分析平稳的信号。我们假设在较短的时间跨度范围内,语音信号的变换是平坦的,这就是为什么要分帧的原因)、加窗,再对每一帧做傅里叶变换(FFT),最后把每一帧的结果沿另一个维度堆叠起来,得到类似于一幅图的二维信号形式。如果我们原始信号是声音信号,那么通过STFT展开得到的二维信号就是所谓的声谱图。
声谱图往往是很大的一张图,为了得到合适大小的声音特征,往往把它通过梅尔标度滤波器组(mel-scale filter banks),变换为梅尔频谱(mel-spectrogram)。在梅尔频谱上做倒谱分析(取对数,做DCT变换)就得到了梅尔倒谱系数(MFCC,Mel Frequency Cepstral Coefficents)。我们主要使用第三方库librosa提取MFCC特征。
CBHG 内部结构说明
所谓 CBHG 就是作者使用的一种用来从序列中提取高层次特征的模块,如下图所示:
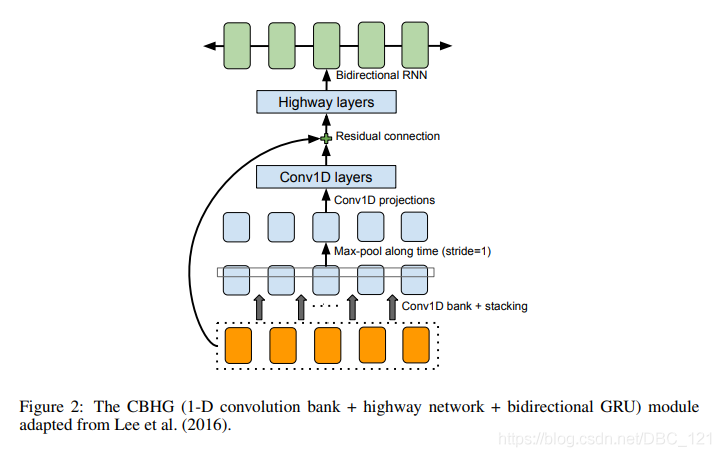
CBHG 使用了 1D 卷积、highway、残差链接和双向 GRU 的组合,输入序列,输出同样也是序列,因此,它从序列中提取表示非常强大。CBHG 架构流程如下:
- 首先使用 $K$ 组 1D 卷积对输入序列进行卷积,其中第 $k$ 组表示为$C_k$ ,其卷积核的宽度为 $k$(即$k=1,2,…,K$)。 这些卷积层显式地对本地和上下文信息进行建模(类似于对 unigram,bigrams 以及 K-gram 的建模)
- 然后将卷积输出堆叠在一起(注意:在做卷积时,运用了padding,因此这k个卷积核输出的大小均是相同的),并进行最大化池,以增加局部不变性。注意了,最大化池使用 stride 为 1 来保留原始时间分辨率
- 接着将处理后的序列传递给一些固定宽度的 1D 卷积,其输出通过残差连接与原始输入序列相加,同时批量归一化用于所有卷积层
- 然后将输出喂到多层 highway 网络中以提取高级特征。highway nets的每一层结构为:把输入同时放入到两个一层的全连接网络中,这两个网络的激活函数分别采用了ReLu和sigmoid函数,假定输入为input,ReLu的输出为output1,sigmoid的输出为output2,那么highway layer的输出为output=output1∗output2+input∗(1−output2)。为什么要使用highway network的结构呢,其实说白了也是一种减少缓解网络加深带来过拟合问题,以及减少较深网络的训练难度的一个trick。它主要受到LSTM门限机制的启发。
- 最后,在顶部堆叠双向 GRU RNN,以从前向和后向上下文中提取顺序特征。
在 Encoder 中,输入被 CBHG 处理之前还需要经过 pre-net 进行预处理,作者设计 pre-net(pre-net 是由全连接层 + dropout 组成的模块)的意图是让它成为一个 bottleneck layer 来提升模型的泛化能力,以及加快收敛速度。
Decoder 结构说明
随后就是 Decoder 了,论文中使用两个 decoder
- attention decoder:attention decoder 用来生成 query vector 作为 attention 的输入,交由注意力模块生成 context vector。它用于学习如何对齐文本序列和语音帧,序列中的每个字符编码通常对应多个语音帧并且相邻的语音帧一般也具有相关性。
- output decoder:output decoder 则将 query vector 和 context vector 组合在一起作为输入。
作者并没有选择直接用 output decoder 来生成 spectrogram,而是生成了 80-band mel-scale spectrogram,也就是我们之前提到的 mel-spectrogram,熟悉信号处理的同学应该知道,spectrogram 的 size 通常是很大的,因此直接生成会非常耗时,而 mel-spectrogram 虽然损失了信息,但是相比 spectrogram 就小了很多,且由于它是针对人耳来设计的,因此对最终生成的波形的质量不会有很多影响。
随后使用 post-processing network(下面会讲)将 seq2seq 目标转换为波形,然后使用一个全连接层来预测 decoder 输出。Decoder 中有一个 trick 就是在每个 decoder step 预测多个 (r 个)非重叠frame,这样做可以缩减计算量,且作者发现这样做还可以加速模型的收敛。
预测多个非重叠帧的直观解释:因为就像我们前面说到的提取音频特征的时候,我们会先分帧,相邻的帧其实是有一定的关联性的,所以每个字符在发音的时候,可能对应了多个帧,因此每个GRU单元输出为多个帧的音频文件。
论文提到 scheduled sampling 在这里使用会损失音频质量
post-processing net 和 waveform synthesis
和seq2seq网络不同的是,tacotron在decoder-RNN输出之后并没有直接将其作为输出通过Griffin-Lim算法合成音频,而是添加了一层post-processing模块。为什么要添加这一层呢?
首先是因为我们使用了Griffin-Lim重建算法,根据频谱生成音频,Griffin-Lim原理是:我们知道相位是描述波形变化的,我们从频谱生成音频的时候,需要考虑连续帧之间相位变化的规律,如果找不到这个规律,生成的信号和原来的信号肯定是不一样的,Griffin Lim算法解决的就是如何不弄坏左右相邻的幅度谱和自身幅度谱的情况下,求一个近似的相位,因为相位最差和最好情况下天壤之别,所有应该会有一个相位变化的迭代方案会比上一次更好一点,而Griffin Lim算法找到了这个方案。这里说了这么多,其实就是Griffin-Lim算法需要看到所有的帧。post-processing可以在一个线性频率范围内预测幅度谱(spectral magnitude)。
其次,post-processing能看到整个解码的序列,而不像seq2seq那样,只能从左至右的运行。它能够通过正向传播和反向传播的结果来修正每一帧的预测错误。
论文中使用了CBHG的结构来作为post-processing net,前面已经详细介绍过。实际上这里 post-processing net 中的 CBHG 是可以被替换成其它模块用来生成其它东西的,比如直接生成 waveform,在 Tacotron2 中,CBHG 就被替换为 Wavenet 来直接生成波形。
模型详细的配置
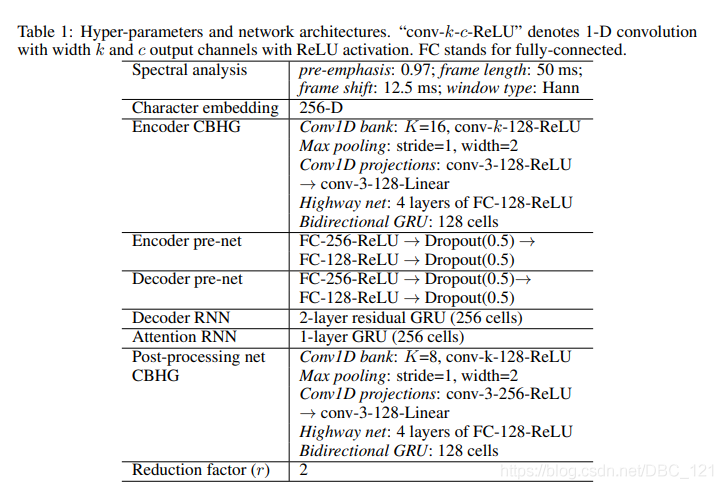
对 Decoder 和 post-processing net 使用 L1 损失,并取平均。作者使用 32batch,并将序列 padding 到最大长度。关于 padding 的说明,Tacotron 原文如下:
It’s a common practice to train sequence models with a loss mask, which masks loss on zero-padded frames. However, we found that models trained this way don’t know when to stop emitting outputs, causing repeated sounds towards the end. One simple trick to get around this problem is to also reconstruct the zero-padded frames.
Tacotron2模型结构
Tacotron有啥缺点呢?
- CBHG模块的去与留?
Tacotron中使用了CBHG模块(包括编码器部分和解码器部分),虽然在实验中发现该模块可以一定程度上减轻过拟合问题,和减少合成语音中的发音错误,但是该模块本身比较复杂,能否用其余更简单的模块替换该模块?
- Attention出现错误对齐的现象
Tacotron中使用的Attention机制能够隐式的进行语音声学参数序列与文本语言特征序列的隐式对齐,但是由于Tacotron中使用的Attention机制没有添加任何的约束,导致模型在训练的时候可能会出现错误对齐的现象,使得合成出的语音出现部分发音段发音不清晰、漏读、重复、无法结束还有误读等问题。
- r值如何设定?
Tacotron中一次可生成r帧梅尔谱,r可以看成一个超参数,r可以设置的大一点,这样可以加快训练速度和合成语音的速度,但是r值如果设置的过大会破坏Attention RNN隐状态的连续性,也会导致错误对齐的现象。
- 声码器的选择
Tacotron使用Griffin-Lim作为vocoder来生成语音波形,这一过程会存在一定的信息丢失,导致合成出的语音音质有所下降(不够自然)。Tacotron 中作者也提到了,这个算法只是一个简单、临时的 neural vocoder 的替代,因此要改进 Tacotron 就需要有一个更好更强大的 vocoder。
接下来我们来看看 Tacotron2,它的模型大体上分为两个部分:
- 具有注意力的循环序列到序列特征预测网络,该网络根据输入字符序列预测梅尔谱帧的序列
- WaveNet 的修改版,可生成以预测的梅尔谱帧为条件的 time-domain waveform 样本
结构图如下:
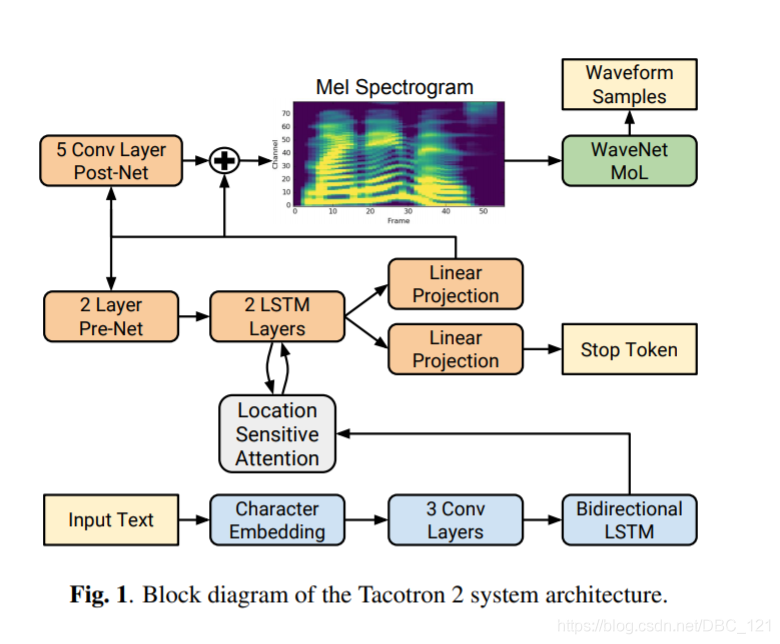
- CBHG模块的去与留?
在Tacotron2中,对于编码器部分的CBHG模块,作者采用了一个3Conv1D+BiLSTM模块进行替代,如图2下方蓝色部分所示;对于解码器部分的CBHG模块,作者使用了Post-Net(5Conv1D)和残差连接进行替代。
- Attention出现错误对齐的现象
在Tacotron2中,作者使用了Location-sensitive Attention代替了原有的基于内容的注意力机制,前者在考虑内容信息的同时,也考虑了位置信息,这样就使得训练模型对齐的过程更加的容易。一定程度上缓解了部分合成的语音发音不清晰、漏读、重复等问题。对于Tacotron中无法在适当的时间结束而导致合成的语音末尾有静音段的问题,作者在Tacotron2中设计了一个stop token进行预测模型应该在什么时候进行停止解码操作。
- r值如何设定?
在Tacotron2中,r值被设定为1,发现模型在一定时间内也是可以被有效训练的。猜测这归功于模型整体的复杂度下降,使得训练变得相对容易。
- 声码器的选择
Tacotron2 选择预测 a low-level acoustic 表示,即 mel-frequency spectrograms(Tacotron 使用 linear-frequency scale spectrograms),Tacotron2 原文描述如下:
This representation is also smoother than waveform samples and is easier to train using a squared error loss because it is invariant to phase within each frame.
mel-frequency spectrogram 与 linear-frequency spectrograms 有关,即短时傅立叶变换(STFT)幅度。mel-frequency 是通过对 STFT 的频率轴进行非线性变换而获得的,同时受到人类听觉系统的启发,用较少的维度表示频率内容,原因很好理解,低频中的细节对于音频质量至关重要,而高频中往往包含摩擦音等噪音,因此通常不需要对高频细节建模。
虽然 linear spectrograms 会丢弃相位信息(因此是有损的),但是诸如 Griffin-Lim 之类的算法能够估算此丢弃的信息,从而可以通过短时傅立叶逆变换进行时域转换。而 mel spectrogram 会丢弃更多信息,因此它的逆问题更具有挑战性,这个时候作者想到了 WaveNet替换了原先的Griffin-Lim,进一步加快了模型训练和推理的速度,因为wavenet可以直接将梅尔谱转换成原始的语音波形。(Tacotron2合成语音音质的提升貌似主要归功于Wavenet替换了原有的Griffin-Lim)。
除了 Wavenet,Tacotron2 和 Tacotron 的主要不同在于:
- 不使用 CBHG,而是使用普通的 LSTM 和 Convolution layer
- decoder 每一步只生成一个 frame
- 增加 post-net,即一个 5 层 CNN 来精调 mel-spectrogram
Tacotron实验结果
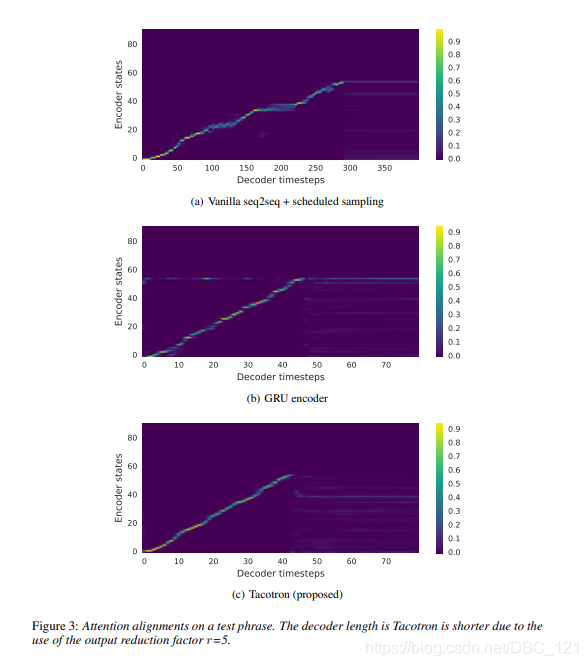
下图展示 Decoder step 中,使用不同组件学习到 attention alignment 的效果:
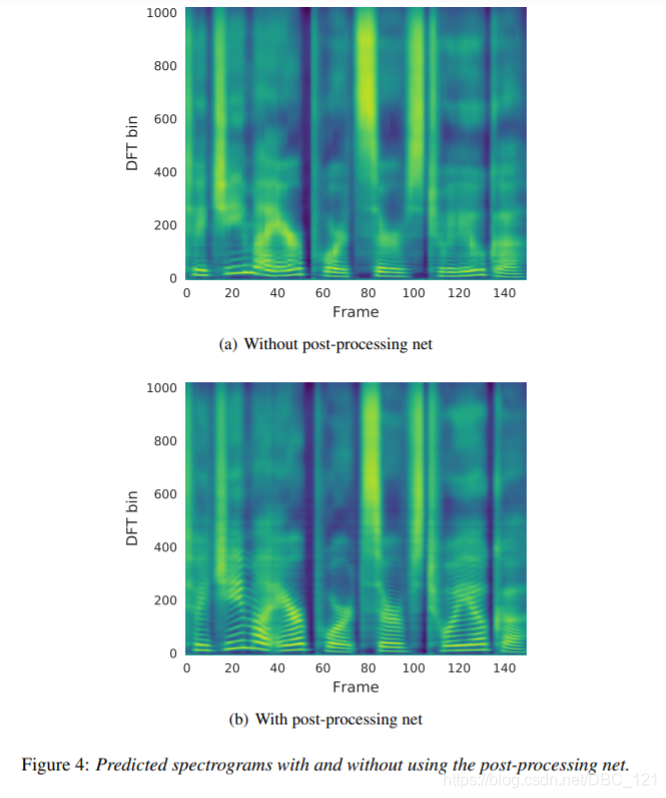
下图展示了 post-processing net 的实验效果,可以看到有 post-processing net 的网络效果更好:
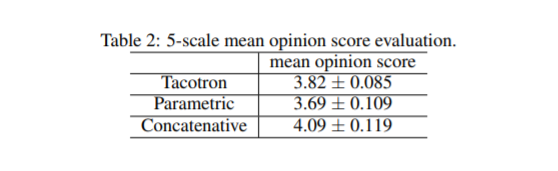
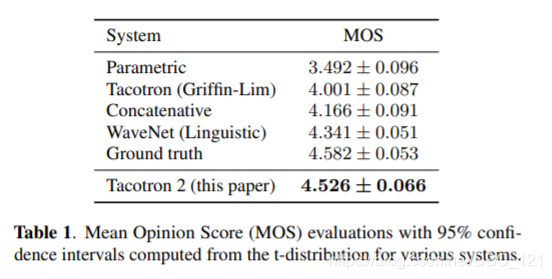
MOS 分数对比如下表:
Tacotron2实验结果
下表展示了 Tacotron2 与各种现有系统的 MOS 分数比较。Tacotron2 的分数已经和人类不相上下了,这在很大程度上要归功于 Wavenet。
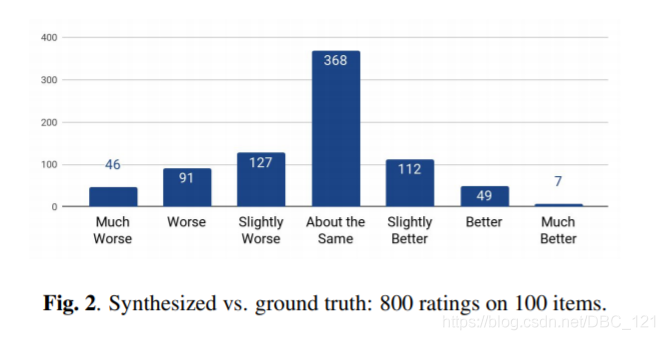
下表是对合成的音频的评价:
文中提到,Wavenet 在这个模型中是和剩下的模型分开训练的,Wavenet 的输入是 mel-spectrogram,输出是 waveform,这个时候就需要考虑输入的 mel-spectrogram 是选择 ground truth,还是选用 prediction,作者做了相关实验,结果如下图所示:
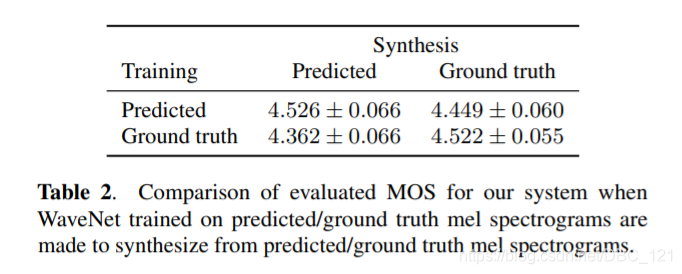
可以看到使用模型生成的 mel-spectrogram 来训练的 Wavenet 取得了最好的结果,作者认为这是因为这种做法保证了数据的一致性。下表是生成 mel-spectrogram 和 linear spectrogram 的区别(结果证明 mel-spectrogram 是最好的,同时还能够减少计算,加快 inference 的时间):
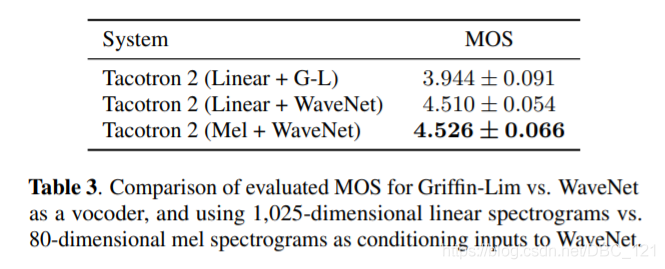
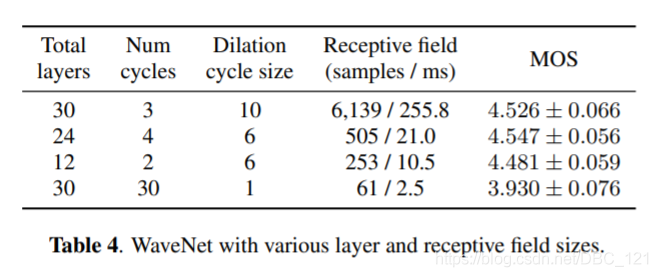
下表是对 WaveNet 简化之后的 MOS 分数情况:
关于 vocoder
声码器(Vocoder)在语音合成中往往被用于将生成的语音特征转换为我们所需要的语音波形。在Tacotron中,由于前端的神经网络所预测出的梅尔谱图仅包含了幅值信息而缺乏相应的相位信息,我们难以直接通过短时傅里叶变换(STFT)的逆变换将梅尔谱图还原为声音波形文件;因此,我们需要使用声码器进行相位估计,并将输入的梅尔谱图转换为语音波形。
Tacotron 使用的是 Griffin-Lim 算法,Griffin-Lim 是一种声码器,常用于语音合成,用于将语音合成系统生成的声学参数转换成语音波形,这种声码器不需要训练,不需要预知相位谱,而是通过帧与帧之间的关系估计相位信息,从而重建语音波形。更正式一点的解释是 Griffin-Lim 算法是一种已知幅度谱,未知相位谱,通过迭代生成相位谱,并用已知的幅度谱和计算得出的相位谱,重建语音波形的方法,具体可参考这篇 Griffin-Lim 声码器介绍。
Griffin-Lim 的优点是算法简单,可以快速建立调研环境,缺点是速度慢,很难在 CPU 上做到实时,无法实时解码也就意味着系统无法在生产环境使用。而且通过Griffin-Lim生成波形过于平滑,空洞较多,听感不佳。
种种迹象表明,Griffin-Lim 算法是音质瓶颈,经过一些列工作尤其是 Tacotron2 ,人们逐渐意识到,Mel-Spectrogram 可以作为采样点自回归模型的 condition,利用强大的采样点自回归模型提高合成质量。
目前公认的效果有保障的采样点自回归模型主要如下几种,1) SampleRNN、2)WaveNet、3)WaveRNN。我们重点介绍前两种。
SampleRNN
其模型结构如下:
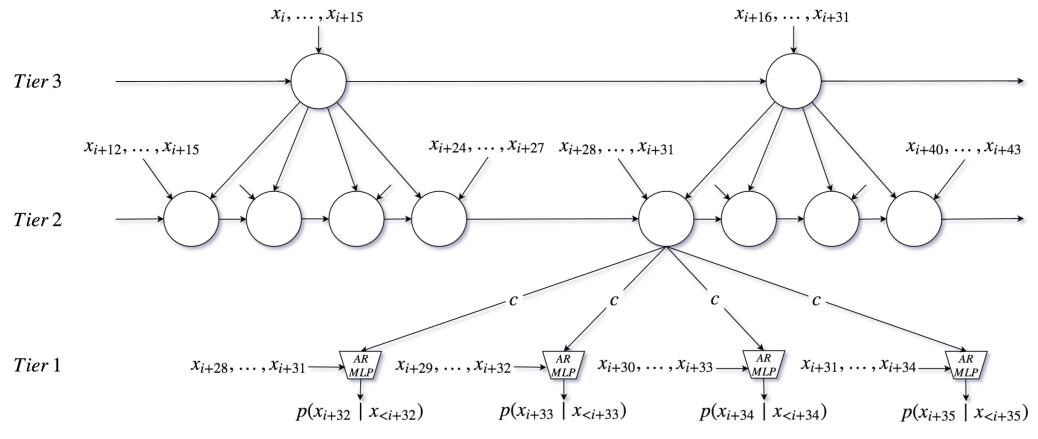
图3: SampleRNN 模型结构
SampleRNN 是一个精心设计的 RNN 自回归模型。标准的 RNN 模型包括 LSTM、GRU,可以用来处理一些长距离依赖的场景,比如语言模型。但对于音频采样点这样的超长距离依赖场景(比如:24k采样率,意味着 1s 中包含 24000 个采样点),RNN 处理起来已经非常困难了 。SampleRNN 的作者,将问题分解,分辨率由低到高逐层建模,例如图中,Tier3 层每时刻输入16个采样点,输出状态 S1;Tier2 层每时刻输入 4 个采样点,同时输入 Tier3 输出的 S1,输出状态 S2 ; Tier1 层每时刻输入 4 个采样点,同时输入 Tier2 输出的 S2,输出一个采样点,由于 Tier1 没有循环结构,同一时刻可以输出 4 个采样点。
如果有兴趣,可以点击 SampleRNN Samples,在里面你能找到总长度为 1小时 的 Samples。
总体来看模型的波形生成能力相当了得,发音、音色以及韵律风格的还原度都非常高。但 SampleRNN 也存在一些问题,最主要的是训练收敛速度太慢了,导致调参优化效率低下,我们将介绍另一个采样点自回归模型 WaveNet,相比 SampleRNN ,WaveNet 不但保留了高水平的波形生成能力,而且还提升了训练速度,单卡训练一天就能获得较好的效果。
WaveNet
其模型结构如下

图4: 采样点自回归 WaveNet
图4, 描述了 WaveNet 这类采样点自回归模型的工作方式,模型输入若干历史采样点,输出下一采样点的预测值,也就是根据历史预测未来。如果你对 NLP 较为熟悉,一定会觉得这种工作方式很像语言模型,没错,只不过音频采样点自回归更难一些罢了,需要考虑更长的历史信息才能保证足够的预测准确率。
WaveNet 最初由 DeepMind 推出,是基于 CNN 的采样点自回归模型,由于 CNN 结构的限制,为了解决长距离依赖问题,必须想办法扩大感受野,但扩大感受野又会增加参数量。为了在扩大感受野和控制参数量间寻找平衡,作者引入所谓“扩展卷积”的结构。如上图所示,“扩张卷积”,也可以称为“空洞卷积”,顾名思义就是计算卷积时跨越若干个点,WaveNet 层叠了多层这种 1D 扩张卷积,卷积核宽度为 2 (Parallel WaveNet 为 3),Dilated 宽度随层数升高而逐渐加大。可以想象,通过这种结构,CNN 感受野随着层数的增多而指数级增加。
训练好了 WaveNet ,我们就可以来合成音频波形了。但是,你会发现这时合成的音频完全没有语义信息,听起来更像是鹦鹉学舌,效果就如上一节 SampleRNN 的样例一样。 要使 WaveNet 合成真正的语音,那么就需要为其添加 condition ,condition 包含了文本的语义信息,这些语义信息可以帮助 WaveNet 合成我们需要的波形,condition 的形式并不唯一,但本文中我们只介绍 Mel-Spectrum condition 。
Mel-Spectrum condition
为什么要引入 Mel-Spectrum condition 呢?有两个原因:其一是为了和 Tacotron 打通,Tacotron 的输出可以直接作为 WaveNet 的输入,构成一套完整的端到端语音合成流水线;其二是因为 Mel-Spectrum 本身包含了丰富的语音语义信息,这些语音语义信息可以支持后期的多人混合训练、以及韵律风格迁移等工作。
下面我们将着重介绍如何在模型中融入 Mel-Spectrum condition 。
由于采样点长度和 Mel-Spectrum 长度不匹配,我们需要想办法将长度对齐,完成这一目标有两种方法:一种是将 Mel-Spectrum 反卷积上采样到采样点长度,另一种是将 Mel-Spectrum 直接复制上采样到采样点长度,两种方案效果差异很小。我们希望模型尽量简洁,故而采用第二种方法,如图6所示。
方便起见,我们借用 Deep Voice1 (图5)来说明。经过复制上采样的 Mel-Spectrum condition,首先需要经过一个 1x1 卷积,使 Mel-Spectrum condition 维度与 WaveNet GAU 输入维度相同,然后分两部分累加送入 GAU 即可,注意,WaveNet 每层 GAU 都需要独立添加 Mel-Spectrum condition。
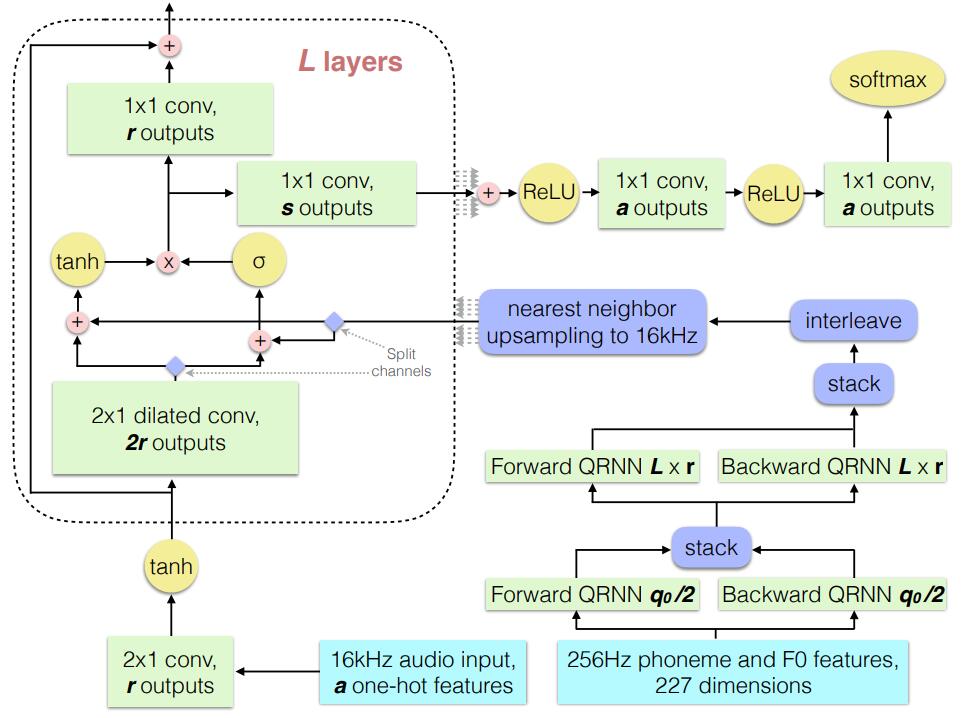
图5: Mel-Spectrum condition 计算方法
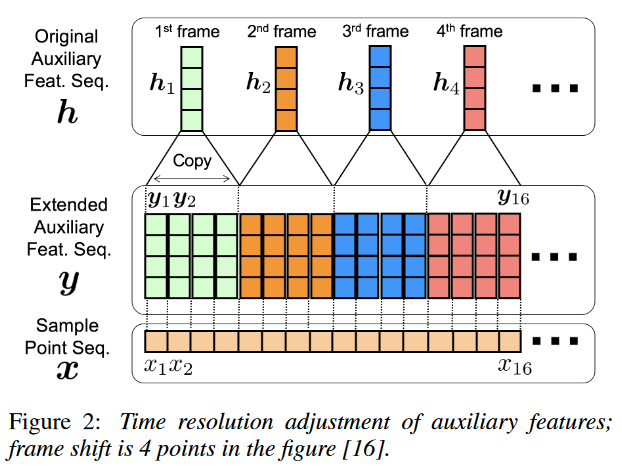
图6: Mel-Spectrum 时间分辨率对齐
WaveNet 有很多优点,训练快、效果好、网络结构清晰简洁。但 WaveNet 也引入了新问题:inference 性能差,在 CPU 平台通常需要数十秒时间合成一秒语音,这让商业化几乎不可能。
针对这一问题,DeepMind 推出了 WaveNet 加速方案 Parallel WaveNet,Parallel WaveNet 将 inference 速度提升上千倍。
Transformer TTS
动机
该方法来自于Neural Speech Synthesis with Transformer Network (2018)。
虽然Tacotron2解决了一些在Tacotron中存在的问题,但是Tacotron2和Tacotron整体结构依然一样,二者都是一个自回归模型,也就是每一次的解码操作都需要先前的解码信息,导致模型难以进行并行计算训练和推理过程中的效率低下。其次,二者在编码上下文信息的时候,都使用了LSTM进行建模。理论上,LSTM可以建模长距离的上下文信息,但是实际应用上,LSTM对于建模较长距离的上下文信息能力并不强。
模型结构
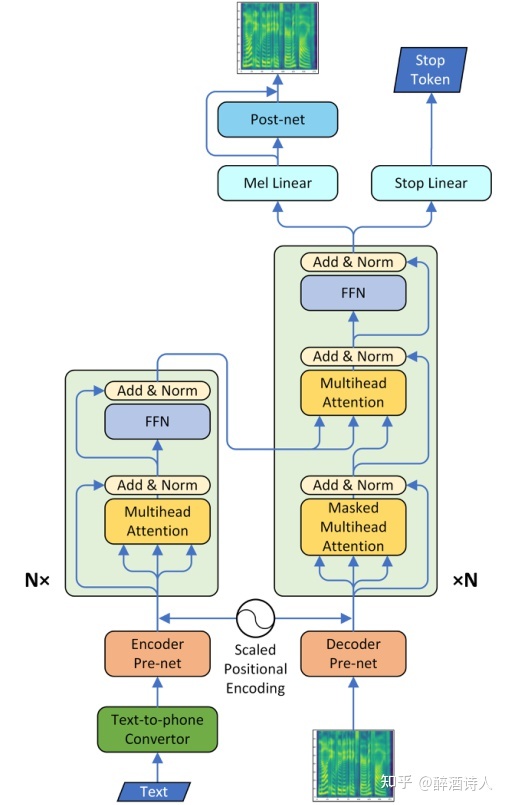
如果对Tacotron2和Transformer比较熟悉的话,可以从上图3中看出,其实Transformer TTS就是Tacotron2和Transformer的结合体。其中,一方面,Transformer TTS继承了Transformer Encoder,MHAttention,Decoder的整体架构;另一方面,Transformer TTS的Encoder Pre-net、Decoder Pre-net、Post-net、stop Linear皆来自于Tacotron2,所起的作用也都一致。换句话说,
将Tacotron2: Encoder BiLSTM ——>Transformer: Multi-head Attention(+positional encoding);
Tacotron2: Decoder Location-sensitive Attention + LSTM ——>Transformer: Multi-head Attention (+positional encoding);
其余保持不变,就变成了Transformer TTS。
也正是Transformer相对于LSTM的优势,使得Transformer TTS解决了Tacotron2中存在的训练速度低下和难以建立长依赖性模型的问题。
其中值得一提的是,Transformer TTS保留了原始Transformer中的scaled positional encoding信息。为什么非得保留这个呢?原因就是Multi-head Attention无法对序列的时序信息进行建模。可以用下列公式表示:
其中,$ \alpha $ 是可训练的权重,使得编码器和解码器预处理网络可以学习到输入音素级别对梅尔谱帧级别的尺度适应关系。
总结
本文作者结合Tacotron2和Transformer提出了Transformer TTS,在一定程度上解决了Tacotron2中存在的一些问题。但仍然存在一些问题:如1)在训练的时候可以并行计算,但是在推理的时候,模型依旧是自回归结构,运算无法并行化处理;2)相比于Tacotron2,位置编码导致模型无法合成任意长度的语音;3)Attention encoder-decoder依旧存在错误对齐的现象。
有关代码解读可以参考声学模型(02):Transformer based TTS
Fastspeech
该算法来自于 FastSpeech: Fast, Robust and Controllable Text to Speech (2019)。
动机
在先前基于神经网络的TTS系统中,mel-spectrogram是以自回归(auto-regressive)方式产生的。由于mel-spectrogram的长序列和自回归性质,这些系统依旧面临着几个问题:
- 在推理阶段,mel-spectrogram生成的速度很慢(slow inference speed)。尽管Transformer TTS相比较基于RNN的模型显著加快了训练速度,但是这些模型在推理阶段都会基于先前生成的mel-spectrogram帧来生成当前时刻的mel-spectrogram帧,导致推理速度较慢。
- 合成语音通常不够稳定(not robust)。由于自回归生成中的错误传播和文本与语音之间存在的错误注意力对齐(传统语音合成系统的Alignment是隐式的导致的),生成的mel-spectrogram通常存在跳词和重复(skip and repeat)问题。
- 合成语音缺乏可控性(lack of controllability),如语速和韵律方面的可控性(这里笔者的可控应该主要指的是生成的语速方面,因为在Prosody的层面已经有工作做到了很好的效果)。
基于以上动机,作者提出了Fastspeech。作者描述到:与自回归TTS模型相比,FastSpeech在mel谱图生成上实现了270倍的加速,在最终语音合成上实现了38倍的加速,几乎消除了跳词和重复的问题,并且可以平滑地调整语音速度。
模型结构
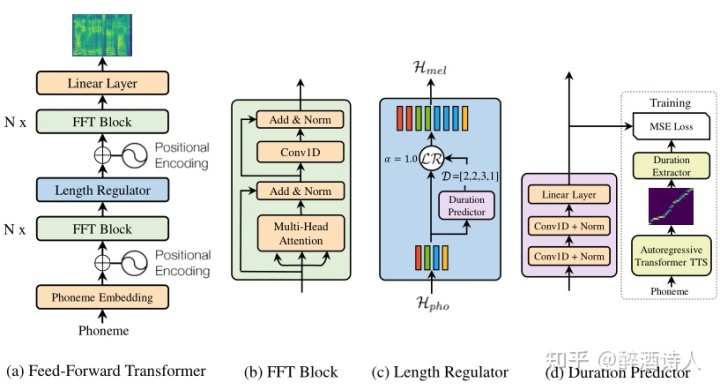
如图1所示,Fastspeech的整体框架和Transformer的Encoder很像,可以简单的理解为是移除了Decoder部分的Transformer模块,以此实现了模型的并行训练和加快推理速度(采用了non auto-regressive的seq-to-seq模型(如上图(a)),不需要依赖上一个时间步的输入,可以让整个模型真正的并行化)。可以看出,Fastspeech主要由三部分构成:FFT Block,Length Regulator和Duration Predictor。
从图1(a)中可以看出,Fastspeech的整体流程和先前的自回归模型还是有几分相似之处的。
先前的自回归模型流程是:Encoder+Attention(隐式alignment)+Decoder;
Fastspeech的流程是FFT Block+Length Regulator+FFT Block;其中第一个FFT Block可以看成是Encoder部分,第二个FFT Block可以看成是Decoder部分。明显不同的是Length Regulator,可以看成是一种显式的Attention alignment方式,至于为什么下文有介绍。
- Feed-Forward Block
从上图b可以看出,其实这个模块和Transformer中Multihead attention+Feed-forward结构很相似。稍微有点不同的是作者把原始Feed-forward中的全连接层换成了1D卷积层。为什么要这么做呢?作者描述到:其动机是,在语音任务中,相邻的隐藏状态在字符/音素和mel谱图序列中的关系更为密切。说白了就是作者认为在合成语音的时候局部范围的上下文信息更为重要,较远距离的上下文信息则不那么重要。
The motivation is that the adjacent hidden states are more closely related in the character/phoneme and mel-spectrogram sequence in speech tasks.
其余的部分均和Transformer中的一致,包括positional encoding、multi-head attention、LayerNorm、residual connections。
- Length Regulator
正上图a所示,第一个FFT Block模块可以简单理解为把因素序列转为一个隐状态,而第二FFT Block模块可以简单理解为把隐状态转换为mel谱图。这就意味着一个问题,要知道因素序列的长度是普遍远远短于mel谱图的长度,那么模型是怎么知道每一个因素应该到底对应多长时间的mel谱帧呢?
基于以上考虑,作者设计了长度调节器模块(如上图c所示),其作用也就显而易见了,主要是用于解决转换过程中音素和mel谱图序列之间的长度不匹配问题,并且还可以控制语音合成的速度(如何控制下文会有介绍)。
形式上,一个音素映射到mel谱图上帧的个数称为音素的持续时间。根据音素的持续时间d,长度调节器将音素序列的隐藏状态扩大d倍,同时确保隐藏状态的总长度等于mel谱图的长度。可以用公式表示:
其中 $ \mathcal{H}_{p h o}=\left[h_{1}, h_{2}, \ldots, h_{n}\right], \mathcal{D}=\left[d_{1}, d_{2}, \ldots, d_{n}\right], \mathrm{n} $ 表示音素序列的长度,$\quad \sum_{i=1}^{n} d_{i}=m$ , $ \mathrm{m} $ 表示mel谱图的长度,而 $ \alpha $ 就是用来控制合成mel谱图长度的超参数, 以此来控制合成语音的语速。举个例子, 比如说音素序列 $ \mathcal{H}_{p h o}=\left[h_{1}, h_{2}, h_{3}, h_{4}\right] $ 对应的每个音素的持续时间为 $ \mathcal{D}=[2,2,3,1] $, 如果 $ \alpha=1 $,那么长度调节器模块就会将h1复制1次、h2复制1次、h3复制2次、 $ \mathrm{h} 4 $ 不复制,最终得到 $ \mathcal{H}_{m e l}=\left[h_{1}, h_{1}, h_{2}, h_{2}, h_{3}, h_{3}, h_{3}, h_{4}\right] $ 。如果 $ \alpha=0 $.5代表合成的语速为原先的两倍(变快), 则每个音素对应的持续时间为 $ \mathcal{D}=[1,1,1.5,0.5] $,因为时间对应的是mel谱图的帧数,帧数不存在小数之说,所以在实际处理的时候会进行向上取整,也就是
$ \mathcal{D}=[1,1,2,1] $,因此最终得到的 $ \mathcal{H}_{m e l}=\left[h_{1}, h_{2}, h_{3}, h_{3}, h_{4}\right] $ 。如果 $ \alpha=2 $ 代表合成的语速为原先的0.5倍(变慢),原理和上述分析类似, 此处不再阐述。
- Duration Predictor
那么问题就来了,模型应该如何确定每个音素的持续时间呢?为了解决这个问题,作者设计了一个持续时间预测器模块。如图1d所示,持续时间预测器包括一个具有ReLU激活函数的2层1D卷积网络,每层后面都有归一化和dropout层,还有一个额外的线性层来输出一个标量,这个标量就表示预测的音素对应的持续时间。
值得一提的是,训练后的长度预测器只用于TTS推理阶段。在训练阶段,直接使用从训练好的自回归teacher模型中提取的音素长度。
具体来说就是在训练阶段,首先用训练一个auto-regressive的TTS模型,这个时候我们不需要知道phoneme duration。
接下来我们用这个TTS模型来为每个训练数据对儿生成attention alignment(也就是说真实的音素持续时间是由已经训练好的Transformer TTS的multi-head attention提供)。因为multi-head attention,包含多种注意力排列,而不是所有的注意头都表现出对角线的特性(即attention weight分布在对角上)。所以,作者制定了一种方式:$ F=\frac{1}{S} \sum_{s=1}^{S} \max _{1 \leq t \leq T} a_{s, t} $,其中S和T分别代表真实的mel谱图和音素序列的长度、 $ a_{s, t} $ 表示 attention矩阵中第s行第t列的元素的数值,最终选择F最大的head用作attention alignment。
有了上面得到的alignment,我们用下面的式子计算$ \mathcal{D}=\left[d_{1}, d_{2}, \ldots, d_{n}\right] $:
That is, the duration of a phoneme is the number of mel-spectrograms attended to it according to the attention head selected in the above step.
在训练过程中,Duration Predictor模块与Fastspeech一起做联合训练,其预测结果与目标做Loss。
也就是在这个模块中,作者抛弃了传统Encoder+attention+Decoder模型中隐式的attention alignment方式,加入了显式的alignment标签。
总结
在两个小节中我们分析了FastSpeech主要解决了以下三个问题:
1)解决已有自回归模型推理过程中合成语音速度慢的问题;
2)取消了先前模型中编码器-解码器之间的隐式注意力机制,从而避免因为注意力对齐不准而带来的合成语句不稳定的问题;
3)在音素持续时间预测模块中引入了$\alpha$因子,使得合成语音的时长(语速)可控。
但是一些不足也很明显,如:
1)合成语音的质量(上限)会受到teacher模型的严重影响;
2)只能控制合成语音的速度,可控性依旧有限。
代码解读可以参考声学模型(03):Fastspeech。
个人补充一下关于注意力对齐:注意力对齐应该是文本和音频的对齐。假设我们的输入时音素和对应的音频,由于对齐不准,可能导致其中一个音素包含了其它音素的音频或者缺失了一部分,导致跳词和重复的问题。
Fastspeech2
动机
虽然FastSpeech作为一个non-autogressive TTS模型已经取得了比auto-regressive模型如Tacotron更快的生成速度和类似的语音质量,但是FastSpeech仍然存在一些缺点,比如
使用一个auto-regressive的TTS模型作为teacher,训练模型非常耗费时间;
使用知识蒸馏的方式来训练模型会导致信息损失,从而对合成出的语音的音质造成影响。
在FastSpeech 2: Fast and High-Quality End-to-End Text to Speech文章中,作者针对这些问题进行了改进,作者首先摒弃了知识蒸馏的teacher-student训练,采用了直接在ground-truth上训练的方式。其次在模型中引入了更多的可以控制语音的输入,其中既包括我们在FastSpeech中提到的phoneme duration,也包括energy、pitch等新的量。作者将这个模型命名为FastSpeech2。作者在此基础之上提出了FastSpeech2s,这个模型可以直接从text生成语音而不是mel-spectrogram。实验结果证明FastSpeech2的训练速度比FastSpeech加快了3倍,FastSpeech2s有比其它模型更快的合成速度。在音质方面,FastSpeech2和2s都超过了之前auto-regressive模型。
模型结构
模型的整体架构如下图所示:
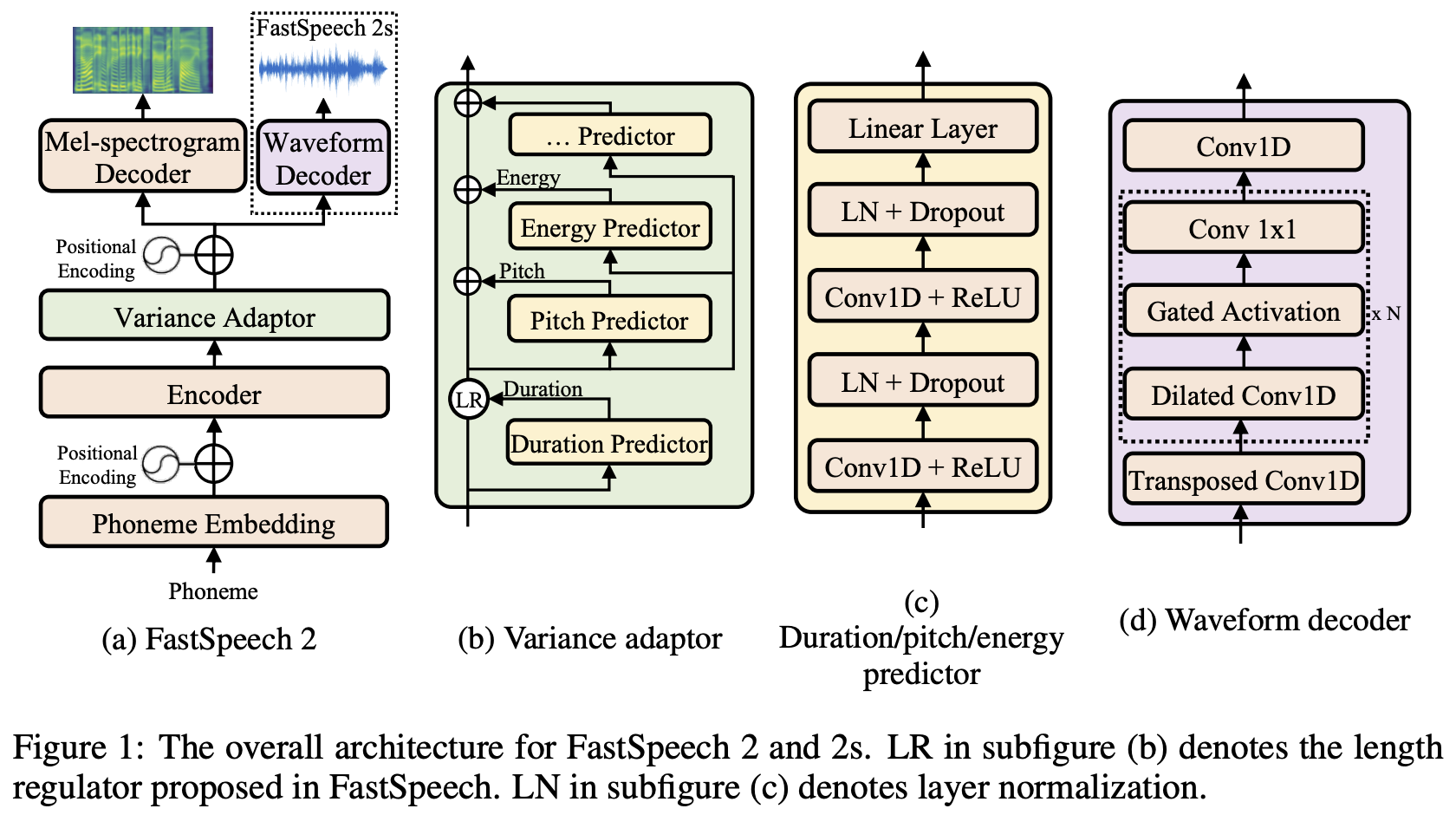
整体上来说(上图(a)),FastSpeech2在encoder和decoder上采用了和FastSpeech类似的基于self-attention和1D卷积的结构。
不同的是,FastSpeech2使用了variance adaptor(上图(b))用来引入更多的输入来控制合成出的语音,正如之前提到的,这里不仅有phoneme duration也有energy和pitch,我们看到这个adaptor的结构使得它可以引入任意多的额外输入。最后,作者没有使用之前的从attention matrix中推断phoneme duration的方法,而是使用了forced alignment得到的duration作为训练的ground truth,实验结果也证明这种方法得到的duration会更加精确。
这里可能一部分的读者不清楚forced alignment是什么。其实这是一种TTS中常用的技术,用来推断音素对应的音频,比如Montreal Forced Aligner (MFA)库。
Variance Adaptor
Variance Adaptor(VA)是给phoneme hidden seq加上变化信息(各种声学特征),对于TTS的one-to-many映射提供帮助。作者在这里加上了三种:duration,pitch和energy。此外像emotion、style、speaker等信息都可以加到VA上。
VA的设计如图(b)所示,GT的duration、pitch、energy一方面被用来在训练时作为condition预测mel谱,另一方面被用来训练声学特征预测器Duration Predictor(DP)、Pitch Predictor(PP)和Energy Predictor(EP)。
Duration Predictor用到了forced alignment抽出的phoneme duration作为训练目标。输入phoneme hidden seq,输出每个音素对应的预测帧数(为便于预测转换成对数域)。DP训练用的是MSE loss,GT 音素时长是通过Montreal Forced Alignment(MFA)工具从原音频中提取的。
Pitch Predictor需要语音的pitch信息作为训练目标,一般情况下会使用pitch contour(基频轮廓),不过这里作者认为pitch contour的variation很大,不好预测。因此作者使用了pitch spectrogram作为训练目标。作者首先使用continuous wavelet transform (连续小波变换,CWT) 获得pitch spectrogram,然后训练predictor去预测它。在合成语音的时候,作者使用inverse CWT (iCWT),即CWT的逆运算来将pitch spectrogram转换称pitch contour。作者进一步根据pitch F0的大小把它们映射到对数域的256个值上 ,最后把值对应的pitch embedding加在phoneme hidden state上,以此为GT target计算MSE loss。
Energy Predictor:对于每一STFT帧计算其幅度的L2范数作为能量值,然后将energy均匀量化成256个可能值,最后将值对应的embedding加到hidden state上。这里训练的时候predictor会直接预测映射之前的energy,并计算MSE loss。
FastSpeech2s
作者希望实现text-to-waveform而不是text-to-mel-to-waveform的合成方式,因此扩展FastSpeech2提出了FastSpeech2s。在上一节的架构图的子图(a)中我们可以看到,FastSpeech2s直接从hidden state中生成waveform,而不使用mel-spectrogram decoder。
架构图的子图(d)给出了waveform decoder的架构,作者使用类似WaveNet的结构,其中包含了dilated卷积和gated activation。这里作者使用了WaveGAN中的对抗训练的方法来让模型隐式地学习到恢复phase information的方法。值得注意的是这里作者在训练FastSpeech2s的时候也同时训练FastSpeech2的mel-spectrogram decoder,作者认为这样可以从text中提取更多的信息。
总结
本文介绍了FastSpeech的改进版FastSpeech2/2s,FastSpeech2改进了FastSpeech的训练方法,通过引入forced alignment以及pitch和energy信息提升了模型的训练速度和精度。FastSpeech2s进一步实现了text-to-waveform的训练方式,因此提升了合成速度。实验结果证明FastSpeech2的训练速度比FastSpeech快了3倍,另外FastSpeech2s由于不需要生成mel-spectrogram因此有更快的合成速度。
参考
论文阅读笔记:Tacotron和Tacotron2
语音合成(三):端到端的TTS深度学习模型tacotron
Tacotron以及Tacotron2详解
端到端语音合成及其优化实践(上)
语音合成简介 Text-to-speech
语音合成技术综述
声学模型(02):Transformer based TTS
声学模型(03):Fastspeech
FastSpeech阅读笔记
FastSpeech2——快速高质量语音合成
TTS paper阅读:FastSpeech 2

