ToTensor
Pytorch中有ToTensor()函数,经常用在加载数据的时候。注意该函数的API文档是这样说的:
1 | """Convert a ``PIL Image`` or ``numpy.ndarray`` to tensor. |
也就是说,当该函数的输入为numpy.ndarray (H x W x C) np.uint8或者PIL Image(L, LA, P, I, F, RGB, YCbCr, RGBA, CMYK, 1)的时候,会对数据进行归一化处理。对于图像分割任务,一二分类为例,当类标为{0,1}的时候,满足以上条件,照样会对数据进行预处理。此时,类标就会变成很小的数,导致网络预测出的结果全为0。
值得注意的是,torchvision0.2.0并没有上面输入的前提,全部会归一化,也就是说下面的代码是错误的,而在torchvision0.2.0没有问题。
1 | mask = Image.open(mask_path) |
对于这种情况,可以使用torch.from_numpy用法。避免不同torchvision版本的不同造成错误的影响。
1 | mask = Image.open(mask_path) |
同样的,对于输入数据而言,使用ToTensor()的时候,也会归一化。例如下面代码:
1 | image = self.image_transform(img) |
这里的数据首先经过resize函数进行resize,接着使用ToTensor()函数归一化。最终使用transforms.Normalize函数标准化。可以看到这里使用transforms.Normalize函数的失活,均值和方差均小于1,这也是因为ToTensor()函数会对数据归一化的体现。而我之前使用Tensorflow的时候,因为没有经过归一化,所以标准化的时候,数据各个通道的均值为[103.939, 116.779, 123.68]。
model.zero_grad() vs optimizer.zero_grad()
- 引言
在PyTorch中,对模型参数的梯度置0时通常使用两种方式:model.zero_grad()和optimizer.zero_grad()。二者在训练代码都很常见,那么二者的区别在哪里呢?
- model.zero_grad()
model.zero_grad()的作用是将所有模型参数的梯度置为0。其源码如下:
1 | for p in self.parameters(): |
- optimizer.zero_grad()
optimizer.zero_grad()的作用是清除所有优化的torch.Tensor的梯度。其源码如下:
1 | for group in self.param_groups: |
- 总结
- 当使用
optimizer = optim.Optimizer(net.parameters())设置优化器时,此时优化器中的param_groups等于模型中的parameters(),此时,二者是等效的,从二者的源码中也可以看出来。 - 当多个模型使用同一个优化器时,二者是不同的,此时需要根据实际情况选择梯度的清除方式。
- 当一个模型使用多个优化器时,二者是不同的,此时需要根据实际情况选择梯度的清除方式。
bilinear中的align=True or False
关于blinear中 api里面的align=True和False,其实就是角点是否对齐的选项。
- 在opencv中,blinear默认调用的是align=False
- 在pytorch和tensorflow中, 可以通过api去切换align
先放一张图直观的理解一下:
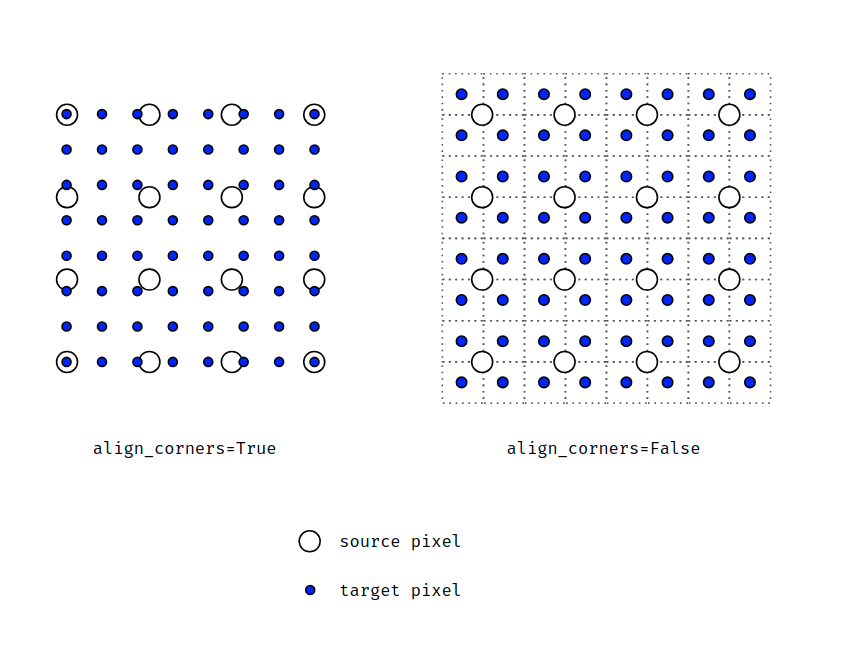
可以明显的看到align_corners=True的时候,角点是对齐状态。而align_cornels=False的时候,角点并没有对齐。
用代码去描述上述的区别为:
1 | # align_corners = False |
1 | # align_corners = True |
参考
PyTorch中的model.zero_grad() vs optimizer.zero_grad()
【图像处理】bilinear中的align=True or False
PyTorch中grid_sample的使用方法
pytorch 模型 .pt, .pth, .pkl的区别及模型保存方式

