GAN
原理
生成对抗网络(GAN)由2个重要的部分构成:
- 生成器(Generator):通过机器生成数据(大部分情况下是图像),目的是“骗过”判别器
- 判别器(Discriminator):判断这张图像是真实的还是机器生成的,目的是找出生成器做的“假数据”

要想理解GAN,直接看损失函数是一个特别好的方法。如下所示,D想办法增加V的值,G想办法减小V的值,两者在相互的对抗。关于V的收敛性证明可以在GAN入门理解及公式推导这里找到。
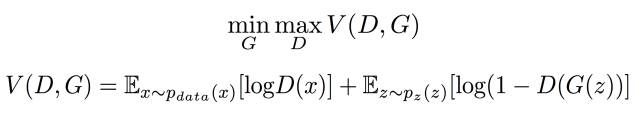
下面介绍一下详细过程:
第一阶段:固定「判别器D」,训练「生成器G」
使用一个较好的判别器D,让一个「生成器G」不断生成“假数据”,然后给这个「判别器D」去判断。一开始,「生成器G」还很弱,所以很容易被揪出来。但是随着不断的训练,「生成器G」技能不断提升,最终骗过了「判别器D」。到了这个时候,「判别器D」基本属于瞎猜的状态,判断是否为假数据的概率为50%。
从损失函数的角度理解,固定D训练G ,它是希望V的值越小越好,让D分不开真假数据。如下所示,目标函数的第一项不包含G,是常数,所以可以直接忽略 不受影响。
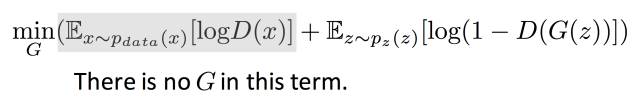
对于G来说,它希望D在划分它的时候能够越大越好,即希望被D划分1(真实数据)。

第二个式子和第一个式子等价。在训练的时候,第二个式子训练效果比较好 常用第二个式子的形式。
第二阶段:固定「生成器G」,训练「判别器D」
当通过了第一阶段,继续训练「生成器G」就没有意义了。这个时候我们固定「生成器G」,然后开始训练「判别器D」。「判别器D」通过不断训练,提高了自己的鉴别能力,最终它可以准确的判断出所有的假图片。到了这个时候,「生成器G」已经无法骗过「判别器D」。

从损失函数的角度理解,训练D的目的是希望这个式子的值越大越好。真实数据希望被D分成1,生成数据希望被分成0。
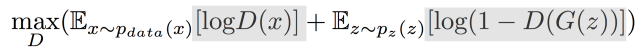
第一项,如果有一个真实数据被分错,那么log(D(x))<<0,期望会变成负无穷大。
第二项,如果被分错成1的话,第二项也会是负无穷大。
很多被分错的话,就会出现很多负无穷,那样可以优化的空间还有很多。可以修正参数,使V的数值增大。
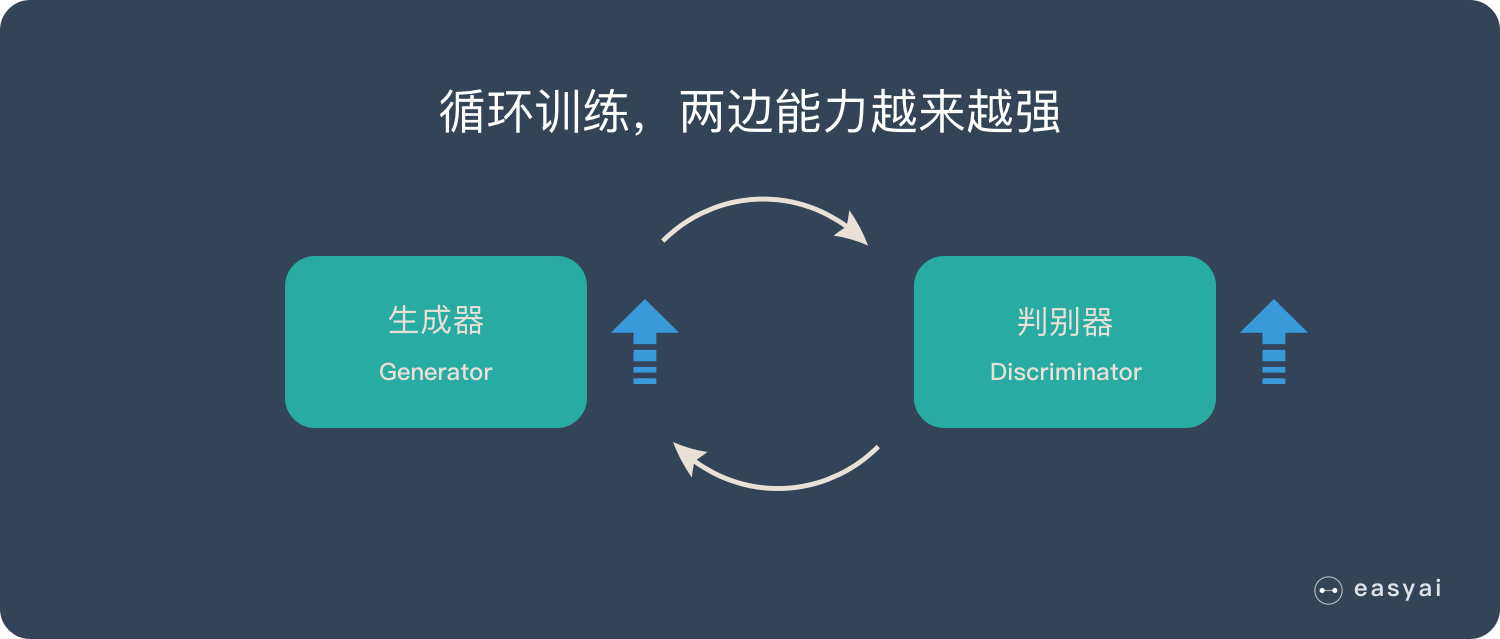
循环阶段一和阶段二
通过不断的循环,「生成器G」和「判别器D」的能力都越来越强。最终我们得到了一个效果非常好的「生成器G」,我们就可以用它来生成想要的图片了。
优缺点
3个优势
- 能更好建模数据分布(图像更锐利、清晰)
- 理论上,GANs 能训练任何一种生成器网络。其他的框架需要生成器网络有一些特定的函数形式,比如输出层是高斯的。
- 无需利用马尔科夫链反复采样,无需在学习过程中进行推断,没有复杂的变分下界,避开近似计算棘手的概率的难题。
2个缺陷
- 难训练,不稳定。生成器和判别器之间需要很好的同步,但是在实际训练中很容易D收敛,G发散。D/G 的训练需要精心的设计。
- 模式缺失(Mode Collapse)问题。GANs的学习过程可能出现模式缺失,生成器开始退化,总是生成同样的样本点,无法继续学习。
扩展阅读:《为什么训练生成对抗网络如此困难?》阅读这篇文章对数学要求很高。
CycleGAN
原理
通常的GAN的设计思路从信息流的角度出发是单向的,如下图所示:使用Generator从A产生一个假的B,然后使用Determinator判断这个假的B是否属于B集合,并将这个信息反馈至Generator,然后通过逐次分别提高Generator与Discriminator的能力以期达到使Generator能以假乱真的能力,这样的设计思路在一般有匹配图像的情况下是合理的,例如Pix2Pix模型的关键是提供了在这两个域中有相同数据的训练样本。
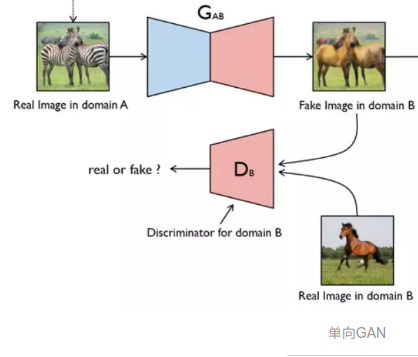
然而若两个域内没有相同数据的训练样本,也就是没有成对样本,则需要借助于CycleGAN。成对样本与非成对样本的示意图如下所示:
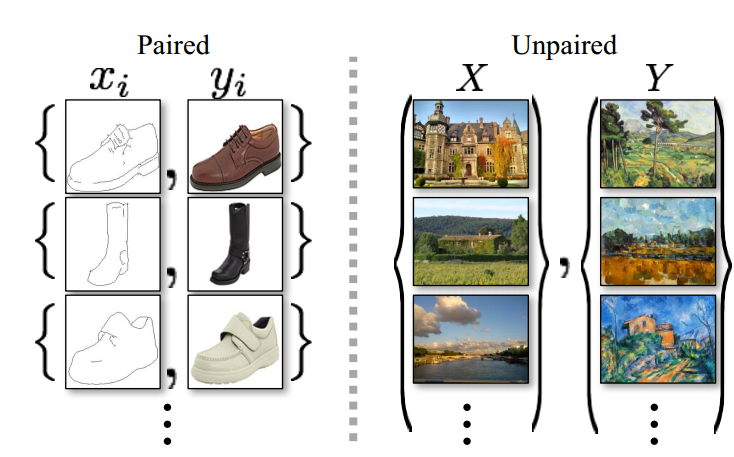
可以实现无配对的两个图片集的训练是CycleGAN与Pixel2Pixel相比的一个典型优点,但仍然需要通过训练创建这个映射来确保输入图像和生成图像间存在有意义的关联,即输入输出共享一些特征。
简而言之,该模型通过从域DA获取输入图像,该输入图像被传递到第一个生成器GeneratorA→B,其任务是将来自域DA的给定图像转换到目标域DB中的图像。然后这个新生成的图像被传递到另一个生成器GeneratorB→A,其任务是在原始域DA转换回图像CyclicA,这里可与自动编码器作对比。这个输出图像必须与原始输入图像相似,用来定义非配对数据集中原来不存在的有意义映射。
量子位给出的CycleGAN的示意图如下:
上图中之所以是
input_A参与D_A损失函数的计算,可以看具体的损失函数。
论文的设计示意图如下:

李宏毅的一张ppt Slide给出的下面的示意图:
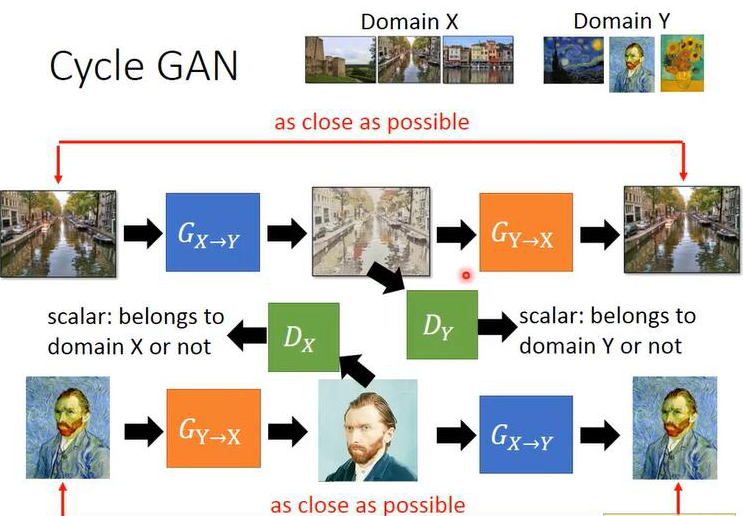
上面的这三个示意图可以结合这一块理解,感觉画的都不错。
GAN个人感觉还是结合具体的损失函数比较好理解。
Cycle-GAN的loss总体来说可以分为两部分,一部分是GAN loss,一部分是Cycle loss:
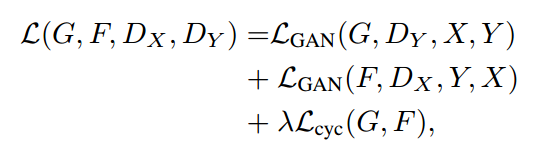
具体每一部分的形式为:
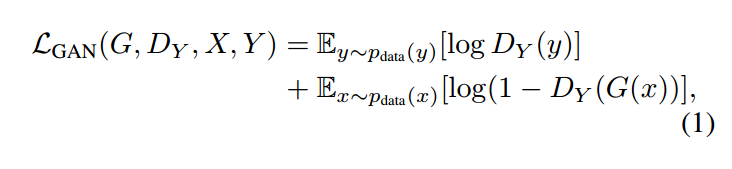
上面这个部分是GAN的损失。从理论上讲,对抗训练可以学习和产生与目标域Y和X相同分布的输出,即映射G和F。然而,在足够大的样本容量下,网络可以将相同的输入图像集合映射到目标域中图像的任何随机排列,其中任何学习的映射可以归纳出与目标分布匹配的输出分布。因此,单独的对抗损失Loss不能保证学习函数可以将单个输入$X_i$映射到期望的输出$Y_i$。
因此,作者又定义了一个cycle consistency loss,也就是说把X生成的Y再通过另一个生成器还原到X域,并且我们希望还原的X和原来的输入X尽可能相似。 也就是$G(F(x)) ≈ x$,同理 $F(G(y)) ≈ y$,因此这个循环一致性损失如下:
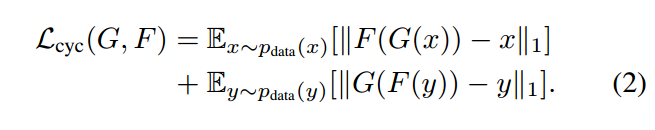
需要注意的是论文中为了保证训练出的模型具有较强的稳定性,将基于前人的成果将GAN loss变为非负的似然计算改为最小平方loss,也就是上面的公式(1)改为了下面的式子:
另外,作者在训练过程中,为了保证稳定性,还使用了GAN训练的“记忆”技术,即在更新Discriminator时使用先期存储的数据而非刚刚由Generator产生数据。
优缺点
CycleGAN实现的是一类图片到另一类图片的转化,也就是图片域的转变, 对于这类问题pix2pix是一种不错的方法,但是pix2pix训练时需要成对的训练样本,也就是比如你要训练图片风景从白天到黑夜的转变,那么你的训练集就是各种风景图片的白天照片以及其对应的黑夜照片,必须一一对应。那么CycleGAN则不需要, 所以如果用CycleGAN来做这个问题,只需要收集一些白天的风景图片和一些黑夜的风景图片即可,不需要是同一种风景,不需要一一对应。
参考
生成对抗网络 – Generative Adversarial Networks | GAN
GAN入门理解及公式推导
CycleGAN介绍
Cycle-GAN 模型介绍——原理简介
CycleGAN原理及实验(TensorFlow)
带你理解CycleGAN,并用TensorFlow轻松实现

